Your AI Agent Should Read Your Notes Before Answering
I have 395 notes in Obsidian and ~2,800 memories from past AI sessions. My AI agent knows none of it unless I paste it in manually. And I can only paste what I remember to paste — which defeats the point of having a knowledge store.
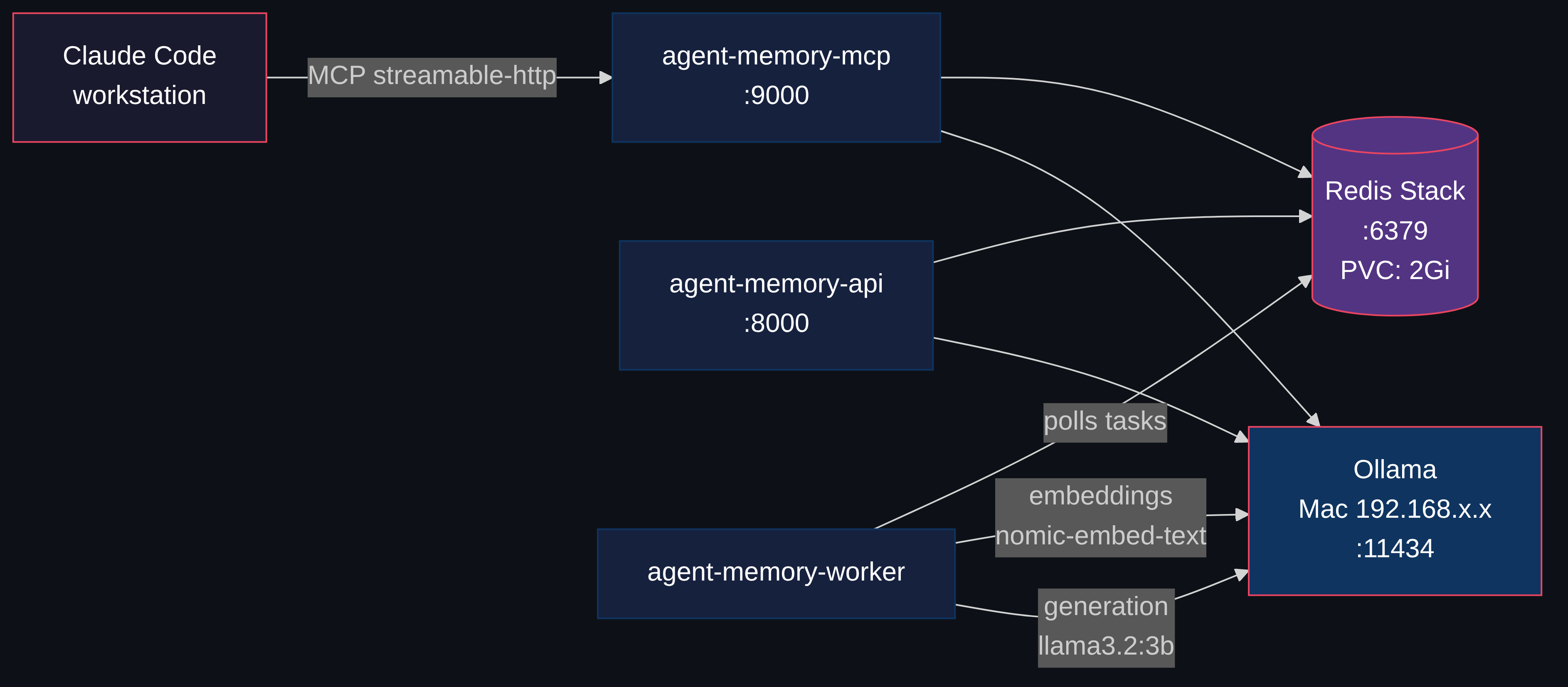
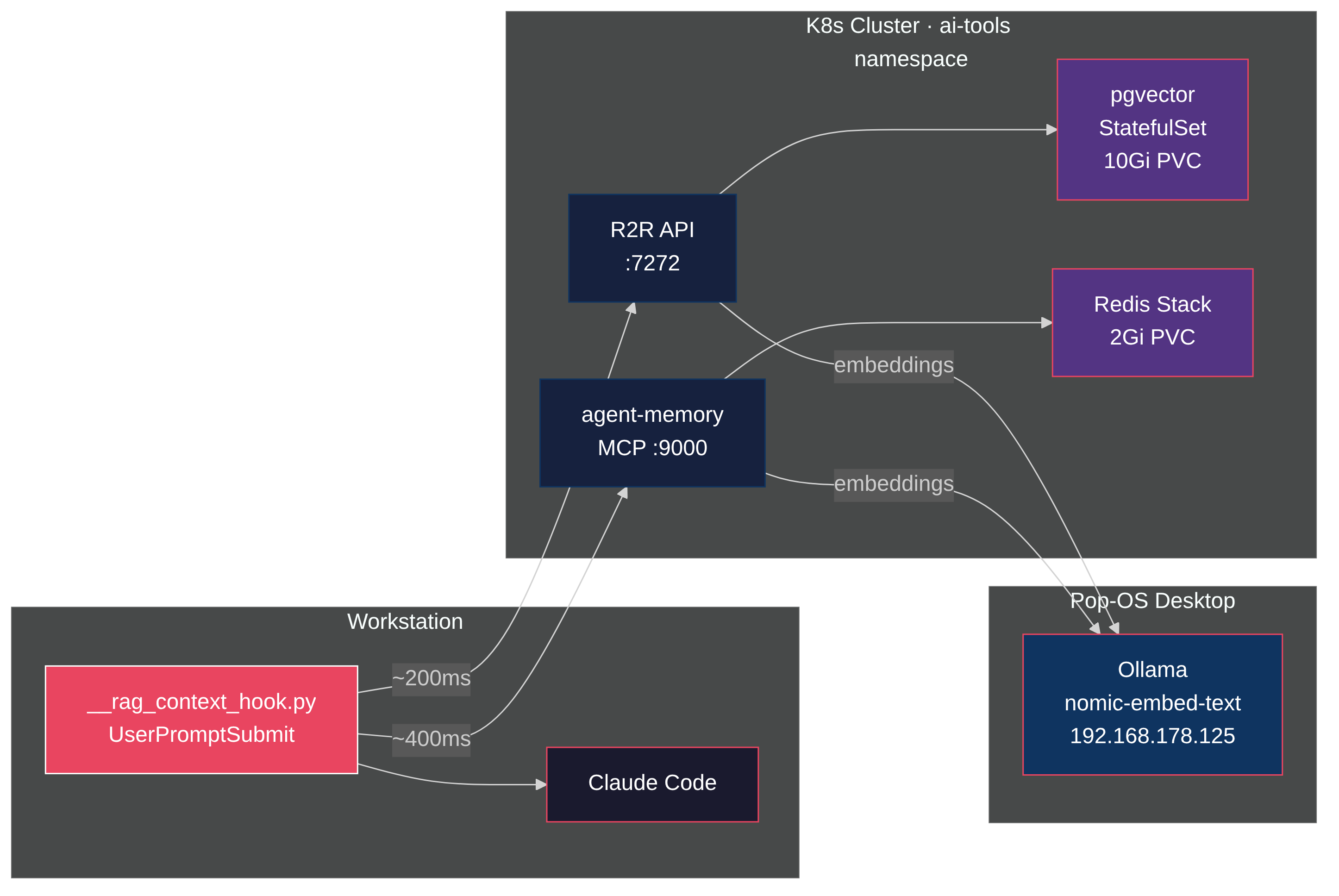
So I built a hook that fires before every prompt, searches a unified vector store, and injects the relevant context before the agent thinks. R2R as the RAG backend, pgvector for storage, Ollama for embeddings, all on a homelab Kubernetes cluster. Total latency: under 100ms. Zero tokens consumed in the retrieval path.
The value isn't the search itself. It's what surfaces when you stop choosing what's relevant. Ask about a Kubernetes pattern and a six-month-old Obsidian note appears. Debug a tmux issue and a memory from a previous session shows up with the exact fix. The agent answers from your accumulated knowledge, not just its training data.