AI agents learn things about you as you work. Your coding style, your infrastructure quirks, which tools you prefer, how you name things. That context accumulates across dozens of sessions. But it evaporates when the session ends or when you switch tools. Use Claude Code in the terminal, Cursor in the IDE, and a web-based MCP client on your phone. Three tools, three isolated memory silos. You can share static knowledge with files. But the context that accumulates from your interactions has nowhere to go.
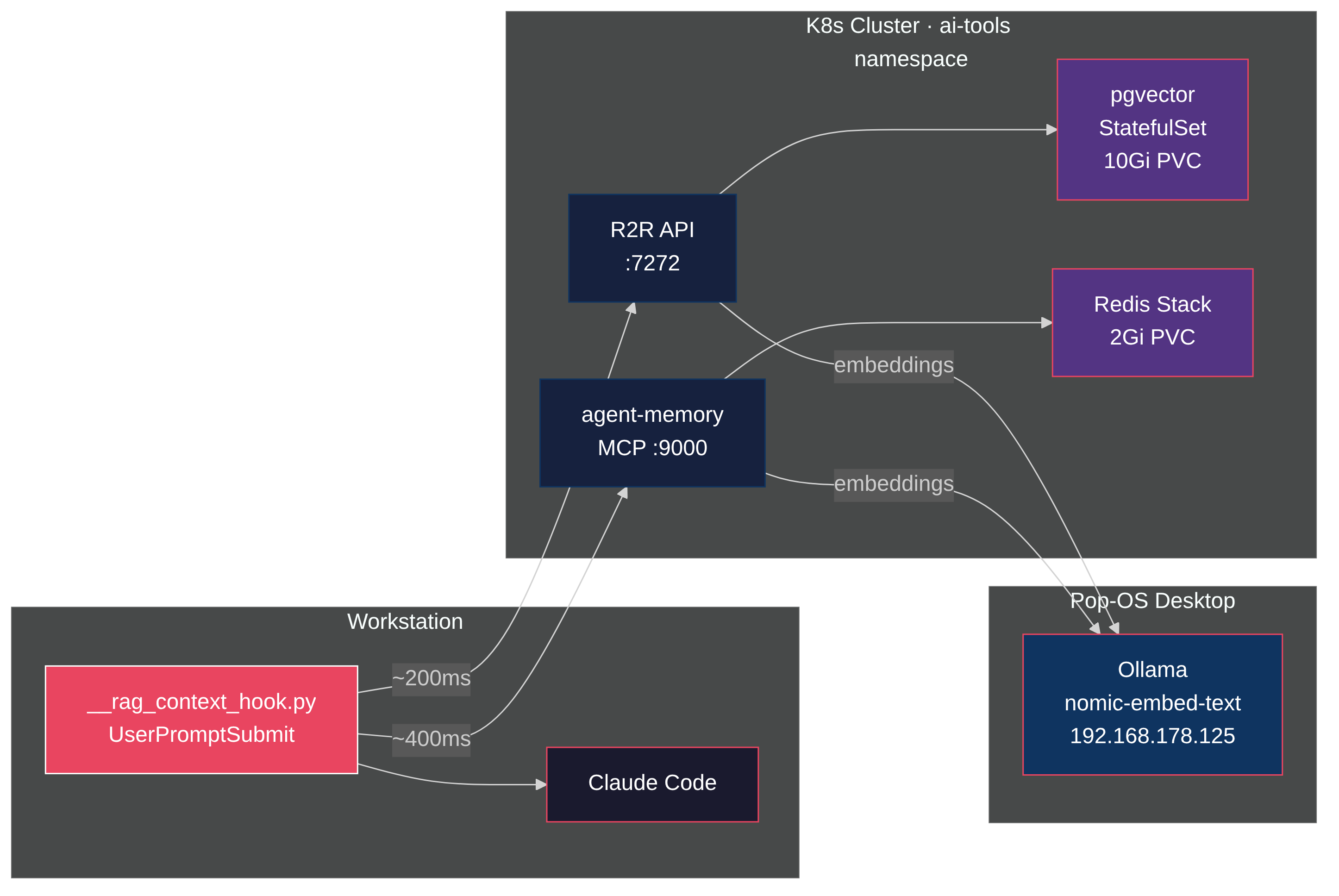
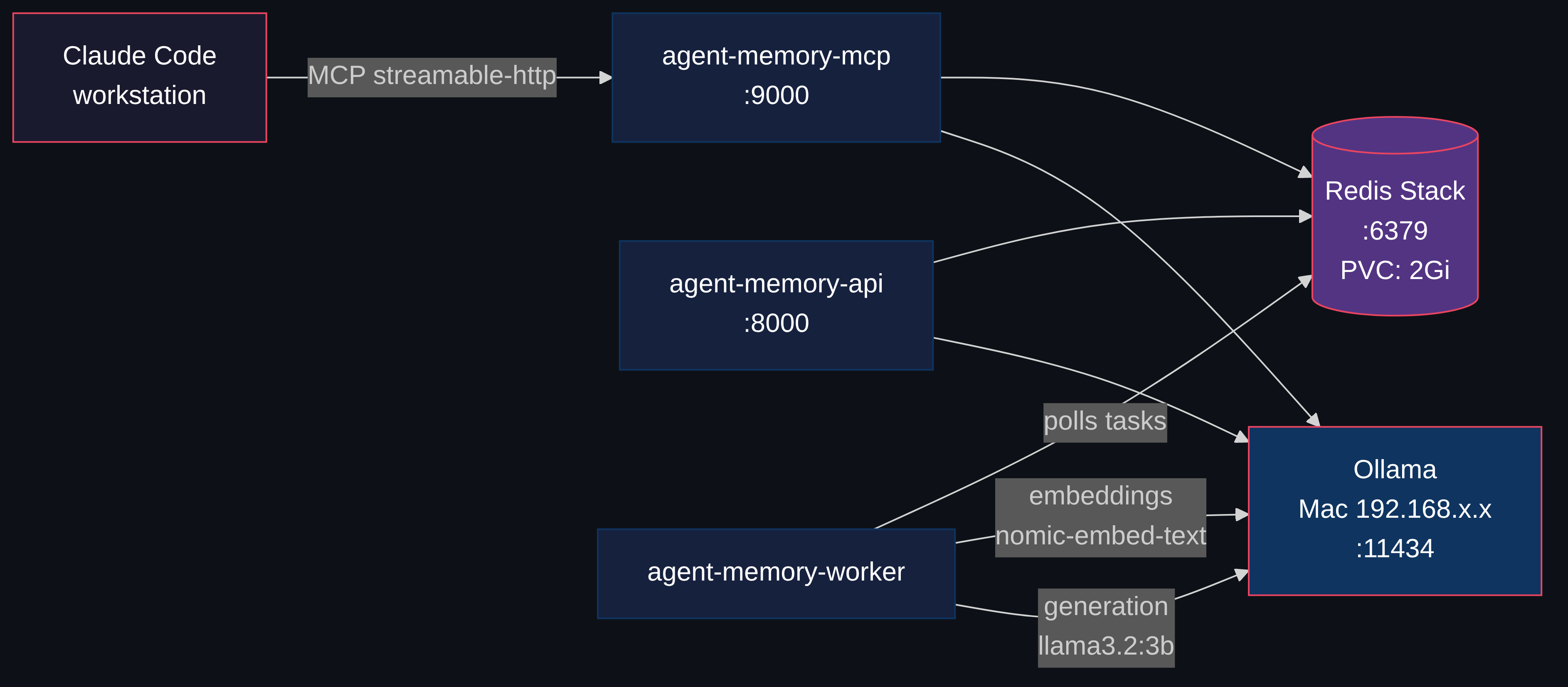
What if the memory layer was separate from the tools entirely? Redis Agent Memory Server does exactly that. It's an open-source memory service that speaks MCP over HTTP. CLI tools (Claude Code, Codex, Gemini CLI), IDE tools (Cursor, Windsurf, Copilot), and any web-based MCP client all connect to the same store. Because the server runs over HTTP, you can expose it beyond the homelab with Cloudflare Tunnels or similar, so tools outside your network connect too. The memory lives on your infrastructure, not theirs.
The server provides two tiers: working memory (session-scoped context that auto-promotes to long-term) and long-term memory (persistent, semantically searchable). It exposes both a REST API and an MCP interface.
I deployed it on my homelab Kubernetes cluster. Four pods, one PVC, zero API costs. Here's how.