Automated Kubetnernetes runbooks
Photo by Markus Winkler on Unsplash
Introduction
Using runbooks can streamline and improve working with Kubernetes by automating repeatable tasks. Bonus point, we can do this using only open source tools.
You will most benefit from this blog if you work in operations, are part of platform or DevOps teams or simply want to learn more about making the experience with Kubernetes easier using automation.
Stay tuned for a video and an interactive scenario covering this topic.
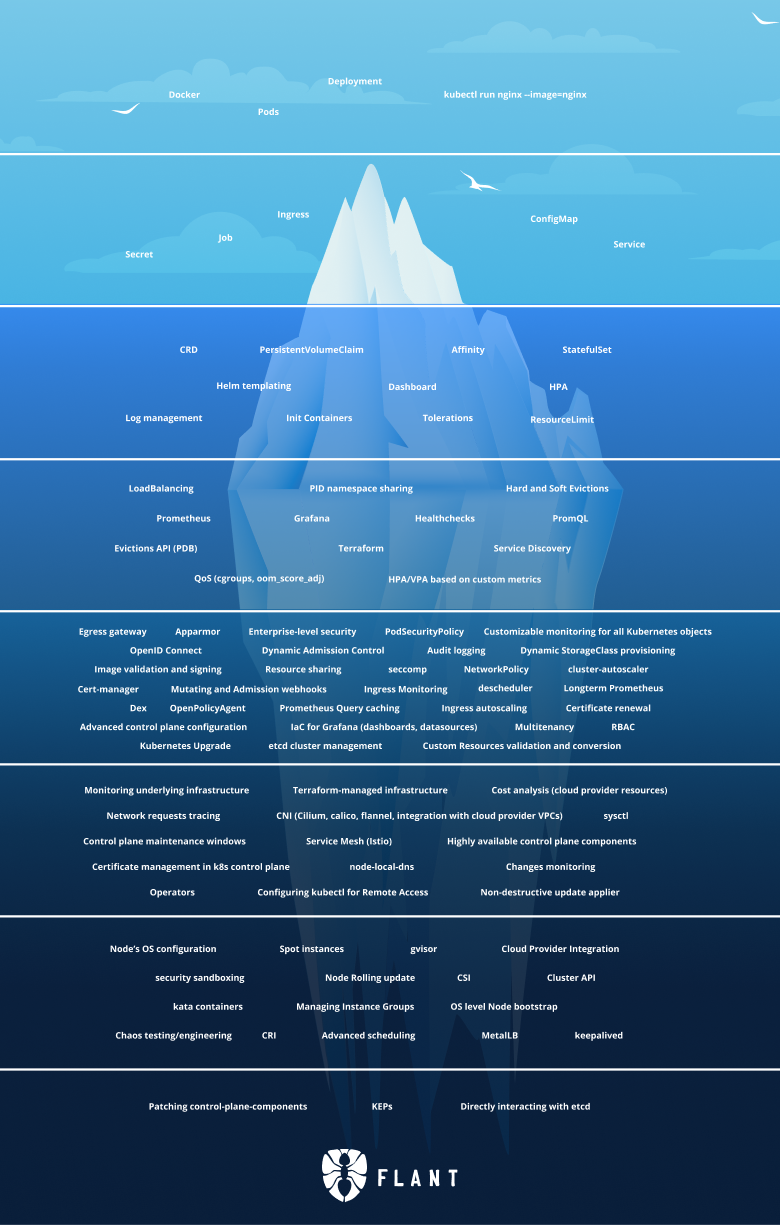
Kubernetes complexity
After learning about pods and deployments, services, config maps and secrets Kubetneres seems not that scary.
As a famous proverb goes.
What you don’t know won’t hurt you.
After a while, your needs exceed what the basic Kubetneres resources can give you and you discover that there is a huge “iceberg” of complexity beneath the surface.
Runbooks
A handy definition by PagerDuty tells us what a runbook is:
A runbook is a detailed “how-to” guide for completing a commonly repeated task or procedure within a company’s IT operations process. Runbooks are created to provide everyone on the team — new or experienced — the knowledge and steps to quickly and accurately resolve a given issue. For example, a runbook may outline routine operations tasks such as patching a server or renewing a website’s SSL certificate.
What are Runbooks for?
Use runbooks to automate 3 common categories of tasks
- handling incidents
- performing repeatable tasks
- problem diagnostics
The diagram below shows a flow starting with incident mitigation and diagnostics to gather information about new issues or repeatable tasks.
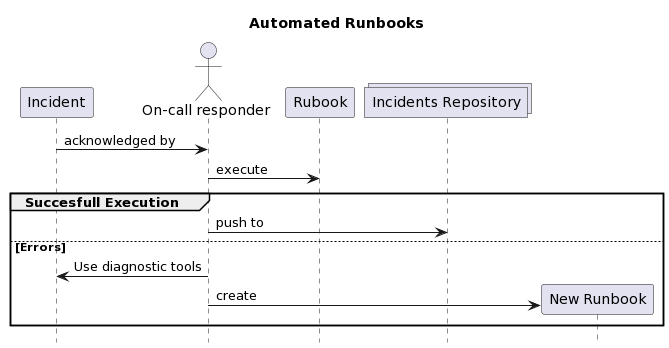
Source: Author
Runbooks of course are not only limited to Kubernetes, but that’s what we are going to focus on today.
Diagnostics
Diagnostics is a special case of a Runbook, where there are a lot of exploratory steps that are not yet captured in the form of a Runbook.
Using and maintaining a dedicated debug container, especially with the ephemeral containers feature helps share best diagnostics practices and tools in the team. This is however a topic for a separate blog!
Automation Goals
Why not just automate everything with a script or a program?
Runbooks are a support tool and guide for tasks that require human intervention and by definition couldn’t be automated. They capture operational knowledge and provide a great source for improvements.
Learnings from building and executing runbooks can and should serve as an inspiration for improving the automation level of the systems they refer to.
How does runbooks automation help?
- Ability to execute runbook steps in a repeatable manner
- Leaving audit trail in the form of incident handling document
- Everyone with access should be able to execute a runbook
Automated Runbooks in Practice
First, create a folder structure with each folder corresponding to a separate Kubernetes cluster. This way we can keep cluster connections cleanly separated.
With time the .kube/config file will contain a mix of dev, test and prod cluster
references. It is easy to forget to switch off from a prod cluster context and
make a mistake and run for example kubectl delete ns crossplane-system.
Use direnv to load k8s config
Use the following setup to avoid these kinds of errors and keep clusters separate.
- Install direnv
Direnv is on most Linux distros and it’s easy to set it up on a Mac
brew install direnvecho eval "$(direnv hook bash)" >> ~/.bashrc # or ~/.zshrc
2. Create a directory per cluster
Especially for connecting to important prod clusters, using a dedicated directory is much safer.
mkdir prod-cluster-xxx && cd prod-cluster-xxx
3. Create .envrc file
This file contains the KUBECONFIG variable that is scoped only to the current directory and all subdirectories
echo export KUBECONFIG="$PWD"/config >> .envrc
Most cloud providers offer a command that merges credentials into the active config file. For example, adding a command
gcloud container clusters get-credentials ...
after setting the KUBECONFIG variable will update with credentials for the
remote GKE cluster in Google Cloud.
The .envrc file can also hold static variables that need to be loaded per
folder such as namespace names, deployment names etc.
4. Enable direnv in the directory
direnv allow
Folder = cluster
Every time you enter the folder, KUBECONFIG variable will change and point to the config file local to the folder. By leaving the folder, direnv will unload the local KUBECONFIG variable and set the previous shell variable.
The Runbooks
Each runbook is simply a markdown file containing with code blocks relevant to the actions we want to perform. Think about them as blueprints for actions you run.
Each runbook is copied from a template file and can be stored in a separate folder with a dedicated `.envrc` file to better capture the results of executing the steps.
Dedicated folders allow for storing notes, troubleshooting steps etc and can be easily converted into git repositories if needed.
Example Runbook
The file itself is a simple markdown with fenced code blocks executed by a code runner and results gathered beneath the commands.
After finishing working with the runbook, the command outputs will be directly underneath the commands. You can/should add comments and additional information about executing the steps.
In the end, commit the new file to arunbooks-repository and use PR process to
merge it and get feedback and improvement suggestions from your colleagues.
Restarting pods
Reference: https://reference-to-runbook-description.com
Make sure to work with the copy of TEMPLATE.md
Timestamp the steps
echo "Steps executed at: $(date)"
Basic cluster info
{
echo -e "\n=== Status ===\n" && \
kubectl get --raw '/healthz?verbose'; echo && \
kubectl get nodes; echo && \
kubectl cluster-info; echo && \
kubectl version; echo;
} | grep -z 'Ready\| ok\|passed\|running'
Kubectl info
kubectl version
Get all pods only in the deployment
Static variables are captures in the .direnv file and loaded on session
startup.
Make sure they are correctly captured.
echo "namespace:" $DEPLOYMENT_NS
echo "deployment:" $DEPLOYMENT
Check pods last restart date
kubectl get pods -n $DEPLOYMENT_NS -o=custom-columns='NAME:.metadata.name,RESTARTS:.status.containerStatuses[*].restartCount,LAST_STARTED:.status.containerStatuses[*].state.running.startedAt'
Capture pod names for the deployment
This steps captures only pods belonging to a deployment and prevents to accidentally label-select pods with the same labels.
RS_NAME=`kubectl describe deployment -n $DEPLOYMENT_NS $DEPLOYMENT | grep "^NewReplicaSet"|awk '{print $2}'`; echo $RS_NAME
POD_HASH_LABEL=`kubectl get rs -n $DEPLOYMENT_NS $RS_NAME -o jsonpath="{.metadata.labels.pod-template-hash}"` ; echo $POD_HASH_LABEL
# export pods names to consume later from other commands
POD_NAMES=`kubectl get pods -n $DEPLOYMENT_NS -l pod-template-hash=$POD_HASH_LABEL --show-labels | tail -n +2 | awk '{print $1}' > pods`
cat pods
Delete pods one by one to force deployment recreation
while read line
do
kubectl delete pod -n $DEPLOYMENT_NS $line
done < pods
Check if problem was fixed
curl -Is https://example-deployment-web-page
Optional: Check health probe
kubectl port-forward --namespace -n $DEPLOYMENT_NS $(kubectl get pod --namespace $DEPLOYMENT_NS --selector="app=deployment" --output jsonpath='{.items[0].metadata.name}') 8080:5000
curl --header 'Accept: application/json' \
--header 'x-health-check: check' \
--include \
--request GET "http://localhost:8080/health/readiness"
## Conclusion
We have seen how using open source tools such as neovim, direnv, git and kubectl
we were able to create a reusable automated runbook.
The library of automated runbooks will grow and contribute to a cleaner and
faster way of handling incidents, more optimized manual configuration tasks and
help capture the results of exploratory diagnostics.