Your AI Agent Should Read Your Notes Before Answering
I have 395 notes in Obsidian and ~2,800 memories from past AI sessions. My AI agent knows none of it unless I paste it in manually. And I can only paste what I remember to paste — which defeats the point of having a knowledge store.
So I built a hook that fires before every prompt, searches a unified vector store, and injects the relevant context before the agent thinks. R2R as the RAG backend, pgvector for storage, Ollama for embeddings, all on a homelab Kubernetes cluster. Total latency: under 100ms. Zero tokens consumed in the retrieval path.
The value isn't the search itself. It's what surfaces when you stop choosing what's relevant. Ask about a Kubernetes pattern and a six-month-old Obsidian note appears. Debug a tmux issue and a memory from a previous session shows up with the exact fix. The agent answers from your accumulated knowledge, not just its training data.
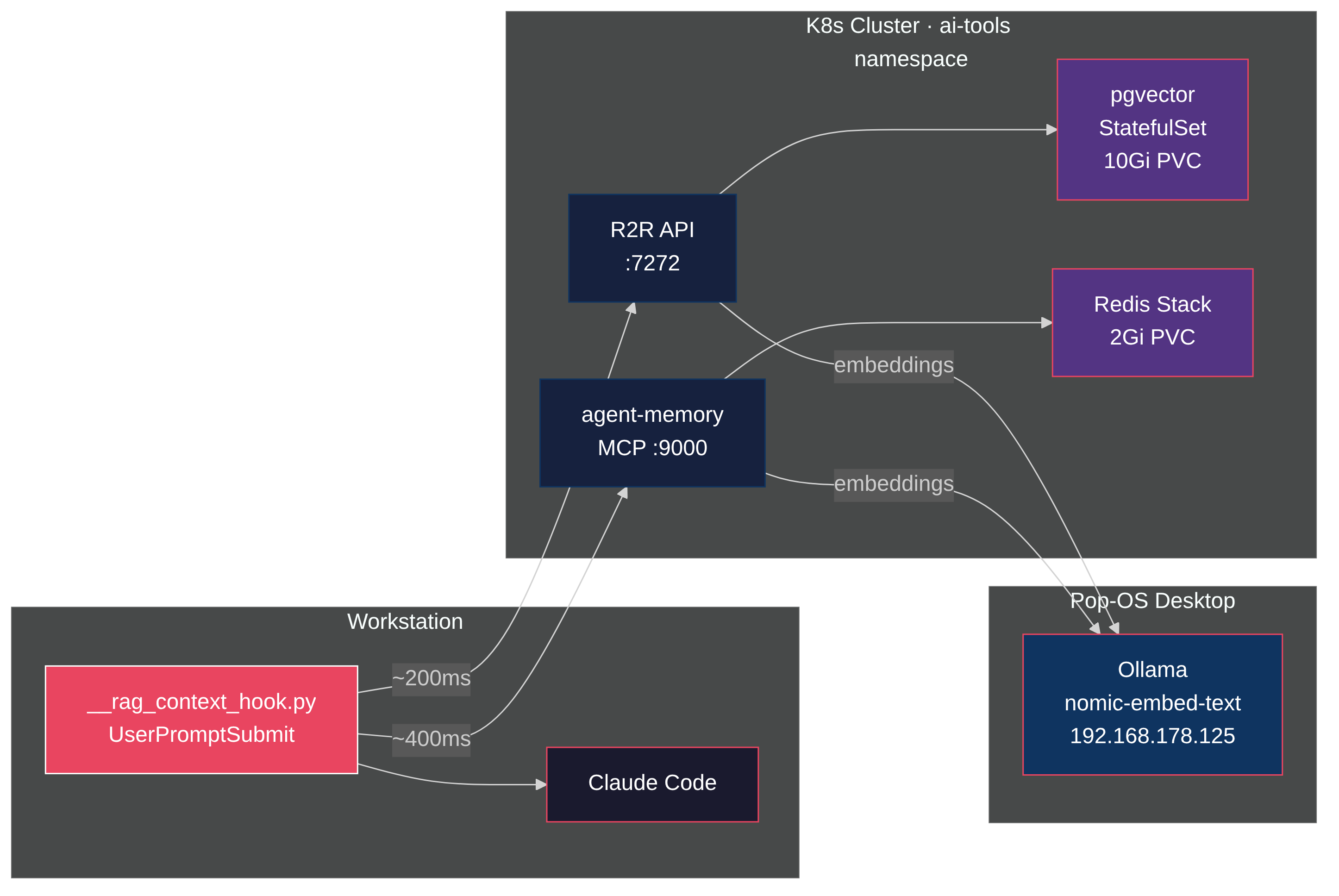
Architecture
Three backend services and one client-side hook.
Each prompt follows this path:
- You type a prompt in Claude Code
- The
UserPromptSubmithook fires before the agent sees it - The hook searches R2R's unified index (~90ms) containing both Obsidian notes and agent memories
- Relevant chunks get injected as
system-remindercontext - The agent sees your prompt plus the matched knowledge
- If a note title looks relevant, the agent drills deeper via the Obsidian MCP server
Two data sources feed a single vector store. A local cron syncs the Obsidian vault into R2R every 30 minutes. A Kubernetes CronJob syncs agent-memory entries every hour. Both land in pgvector with the same embedding model, so a single search covers your curated notes and your session-derived insights.
| Component | Purpose | Storage | Latency |
|---|---|---|---|
| R2R (SciPhi) | Unified search (notes + memories) | pgvector on K8s, 10Gi PVC | ~90ms |
| Obsidian sync | Vault ingestion into R2R | Local cron, every 30min | batch |
| Memory sync | Agent-memory ingestion into R2R | K8s CronJob, every hour | batch |
| Ollama | nomic-embed-text embeddings | System76 Serval WS (RTX 5070 Ti) | <100ms |
| Anthropic Haiku | R2R completions via LiteLLM | Cloud API | on-demand |
How Vector Search Works
The search pipeline runs without an LLM. The key component is an embedding model: nomic-embed-text (274MB), running on Ollama. It converts text into a 768-dimensional vector — a list of 768 floating-point numbers that represent the text's meaning as coordinates in high-dimensional space.
The model was trained on millions of text pairs so that texts with similar meaning land near each other. "Longhorn PVC backup" and "persistent volume restore" end up as nearby points, even though they share zero words.
Ingestion
When the 395 Obsidian notes were loaded into R2R, each note got chunked into segments. Each chunk went to Ollama, which ran it through nomic-embed-text and returned a 768-number vector. pgvector stored both the vector and the original text:
pgvector row:
id: uuid
text: "StatefulSet gets a 10Gi Longhorn PVC..."
embedding: [0.023, -0.187, 0.442, ..., 0.091] (768 floats)
metadata: {title: "r2r-rag-pipeline", source: "obsidian"}
pgvector builds an HNSW index over these vectors so it doesn't compare against every row at query time.
Search
When you type "how do I backup Longhorn volumes?", the hook sends your prompt to Ollama, gets back 768 numbers, and sends those to pgvector. pgvector computes cosine similarity — the angle between your prompt vector and every stored vector — and returns the closest matches. Identical direction = 1.0, orthogonal = 0.0. The threshold is 0.45; anything below gets dropped as irrelevant.
This is pure linear algebra. Dot products and normalization. That's why it runs in ~100ms with zero token costs.
One store, two sources
Both Obsidian notes and agent memories get embedded with nomic-embed-text and stored in pgvector. A single HNSW index covers everything — a prompt about "Longhorn backup" finds relevant hits regardless of whether the knowledge came from a note you wrote or a pattern the agent learned.
| Obsidian notes | Agent memories | |
|---|---|---|
| Sync method | Local cron (every 30min) | K8s CronJob (every hour) |
| Content | Curated technical knowledge | Session-derived insights |
| Chunking | R2R recursive splitter | Whole entries as documents |
| Metadata tag | source: obsidian | source: agent-memory |
The metadata tags let you filter by source if needed, but the default search spans both.
The Database Journey
I started with the CloudNativePG operator. It's the standard for running Postgres on Kubernetes — WAL archiving, automated failover, point-in-time recovery. Production-grade.
It didn't work. Two problems.
First, the pgvector image. CNPG validates container images through a webhook, and pgvector/pgvector:pg17 didn't match the expected image patterns. The webhook rejected the pod.
Second, ImageVolume extensions. CNPG has a mechanism for loading Postgres extensions via ephemeral volumes. The pgvector extension needs to be loaded as a shared library, and the ImageVolume approach hit path resolution issues on my cluster's containerd version.
I spent a day debugging webhook configurations and extension loading. Then I stopped and asked: what am I actually building?
A homelab. Single node. No HA requirement. No point-in-time recovery needed. The data is my Obsidian vault — I have the source of truth on disk. If the database dies, I re-ingest.
A plain StatefulSet with the pgvector/pgvector:pg17 image works:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: r2r-db
namespace: ai-tools
spec:
serviceName: r2r-db
replicas: 1
template:
spec:
containers:
- name: postgres
image: pgvector/pgvector:pg17
env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
- name: init
mountPath: /docker-entrypoint-initdb.d
volumes:
- name: init
configMap:
name: r2r-db-init
An init ConfigMap creates the vector extension:
CREATE EXTENSION IF NOT EXISTS "vector";
The StatefulSet gets a 10Gi Longhorn PVC, a readiness probe on pg_isready, and a Service. Postgres starts, loads pgvector, R2R connects.
Simplicity wins on a homelab. Save the operator for production.
Ingesting the Obsidian Vault
R2R accepts documents through a multipart API. The ingestion script walks the vault directory and uploads each markdown file as raw_text. 395 notes, about three minutes.
Two gotchas during ingestion.
Filenames as DocumentType. R2R parses the uploaded filename to determine document type. Obsidian's zettelkasten IDs (1711476153-YXRZ.md) worked fine. But filenames with special characters got parsed as unknown types. The fix: sanitize filenames before upload and always set the content type to text/plain.
Document summary generation. R2R's default pipeline generates a summary for each ingested document by calling the configured LLM. For 395 documents, that meant 395 Haiku calls during ingestion. Slow, expensive, and unnecessary since I only use vector search, not summaries.
One line in the R2R config fixes it:
[ingestion]
provider = "r2r"
skip_document_summary = true
R2R Configuration
R2R uses LiteLLM under the hood, so you can mix providers. Embeddings run through Ollama (free, local). Haiku is configured as the completion LLM, but the hook only calls R2R's /v3/retrieval/search endpoint — pure vector similarity, no LLM in the loop. Haiku would only fire if you used R2R's RAG endpoint for synthesized answers or re-enabled document summaries.
[completion]
provider = "litellm"
concurrent_request_limit = 16
[app]
quality_llm = "anthropic/claude-3-5-haiku-latest"
fast_llm = "anthropic/claude-3-5-haiku-latest"
[embedding]
provider = "ollama"
base_model = "nomic-embed-text"
base_dimension = 768
The R2R deployment points OLLAMA_API_BASE at the in-cluster Ollama service. Ollama runs on a Pop-OS desktop at 192.168.178.125. A headless Service with manual Endpoints bridges it into the cluster:
apiVersion: v1
kind: Service
metadata:
name: ollama-pc
namespace: ai-tools
annotations:
description: "Pop-OS desktop - always on"
spec:
clusterIP: None
ports:
- port: 11434
targetPort: 11434
name: http
---
apiVersion: v1
kind: Endpoints
metadata:
name: ollama-pc
namespace: ai-tools
subsets:
- addresses:
- ip: 192.168.178.125
ports:
- port: 11434
name: http
Any pod in the cluster reaches Ollama at ollama-pc.ai-tools.svc:11434. No port-forwarding, no NodePorts.
One gotcha: Ollama evicts models from VRAM after five minutes idle. The embedding model kept getting cold-loaded on every RAG request after an idle gap. The fix: keep_alive: -1 in the embed request pins the model permanently.
The RAG Hook
The core of the system is a Python script that Claude Code runs as a UserPromptSubmit hook. It fires on every non-trivial prompt automatically, with an explicit :rag suffix for verbose output. The hook searches R2R's unified index and prints the results to stdout, which Claude Code injects as context.
Hook registration in ~/.claude/settings.json:
{
"hooks": {
"UserPromptSubmit": [
{
"type": "command",
"command": "python3 ~/.claude/scripts/__rag_context_hook.py"
}
]
}
}
The script is 233 lines of stdlib Python. No dependencies beyond what ships with Python 3. Three design decisions matter.
Automatic with escape hatches. The first version was manual-only — you had to type :rag to trigger a search. That meant you only got context when you remembered to ask for it, which defeats the purpose of having a knowledge store. The current version fires on every prompt longer than 20 characters that isn't trivial banter ("ok", "thanks", "ship it"). A regex filter catches these short responses and skips the search. Append :norag to suppress auto-search on a specific prompt. Append :rag for verbose output with scores and timing.
how do I backup longhorn volumes → auto search, compact output
metallb config issue:rag → verbose search with scores
just do it:norag → no search
Single source, single request. Both Obsidian notes and agent memories live in the same pgvector index. One HTTP call to R2R's /v3/retrieval/search endpoint covers everything. No thread pools, no parallel coordination, no partial failure handling. The search takes ~90ms.
payload = json.dumps({
"query": query,
"search_settings": {"limit": limit},
}).encode()
req = urllib.request.Request(
R2R_URL, data=payload,
headers={"Content-Type": "application/json"})
with urllib.request.urlopen(req, timeout=timeout, context=_ssl_ctx) as resp:
body = resp.read()
Tuned relevance threshold. The score threshold sits at 0.45 for both auto and manual modes — high enough to filter noise, low enough to catch useful tangential hits. Auto mode returns 2 results with a 5-second timeout. Manual mode returns 4 results with a 12-second timeout and retries.
The hook prints results in a format Claude Code injects as a system-reminder:
RAG context (Obsidian vault):
[kubernetes-networking] (score: 0.782)
Service mesh configuration requires...
RAG context (agent memory):
[kubernetes, networking, debugging]
When troubleshooting DNS in pods, check...
The agent sees this alongside the prompt. If a note title looks relevant, it reads the full note via the Obsidian MCP server, follows wikilinks, cross-references. The hook provides the signal; the agent decides how deep to go.
Results
The hook adds about 90ms to each prompt. Imperceptible — the agent's thinking time dwarfs it.
| Metric | Value |
|---|---|
| R2R search latency | ~90ms |
| Total hook latency | ~90ms |
| Obsidian notes indexed | 395 |
| Agent memories searchable | ~2,800 |
| Combined documents in pgvector | ~3,200 |
The original architecture searched R2R and agent-memory in parallel — two stores, two HTTP calls, a ThreadPoolExecutor to coordinate them. Agent-memory went through the MCP JSON-RPC layer, adding ~1.7s of overhead. Bypassing MCP and querying Redis FT.SEARCH directly helped, but maintaining two search backends meant two failure modes, two timeout configs, and two relevance thresholds to tune.
The current architecture is simpler. Both data sources sync into R2R on a schedule. One search call covers everything. The hook went from a parallel coordinator to a single HTTP request.
The value shows up in unexpected moments. Ask about a Kubernetes pattern and the hook surfaces an Obsidian note you wrote six months ago. Start debugging a tmux issue and it finds a memory from a previous session where you solved something similar. The agent doesn't just answer from its training data — it answers from your accumulated knowledge.
The entire search pipeline is open source and runs locally. Ollama generates embeddings with nomic-embed-text. pgvector stores and searches vectors. The hook is 233 lines of stdlib Python. Zero API calls, zero tokens consumed, zero billing in the retrieval path. The only cloud dependency is Claude itself interpreting the results.
The two sources complement each other even though they share an index. Obsidian holds curated, structured notes — architecture decisions, tool configurations, blog drafts. Agent-memory holds organic, session-derived insights — "this user prefers bun over npm", "the homelab uses Longhorn for storage", "tmux layouts need xdotool without --sync flags." Together they give the agent both your deliberate knowledge and your implicit patterns.
Links
- R2R -- RAG framework by SciPhi
- pgvector -- vector similarity search for Postgres
- Redis Agent Memory Server -- MCP-native memory service
- Ollama -- local LLM inference
- Claude Code hooks -- pre/post tool execution hooks
- Homelab repo -- full working manifests in
gitops/apps/r2r/